

AI 플랫폼 Runway(런웨이)는 마키나락스가 다양한 기업들과 AI 프로젝트를 진행하면서 쌓은 MLOps 노하우를 정제하여 다음 프로젝트에서 재사용할 수 있도록 만들고, 더 나아가 더 많은 기업이 사용할 수 있도록 제품으로 출시했습니다.
Runway 초기 개발 당시 가장 먼저 마주한 과제 중 하나는 Kubernetes(K8s) 환경에 적합한 데이터베이스를 구성하는 것이었습니다. 이 포스팅에서는 Runway의 K8s-native 데이터베이스를 어떤 고민 끝에 구성했는지, 그 과정에서 어떤 시행착오를 겪었는지, 그리고 지금은 왜 다른 방식을 적용했는지 공유합니다.
처음에는 단순한 K8s 배포로 PostgreSQL을 시작했습니다
데이터베이스 구축을 위한 초기 선택은 PostgreSQL을 K8s 환경에 k8s.Deployment로 배포하는 형태였습니다. 이 선택이 별로 좋아 보이지 않는다면 제대로 보신 겁니다. k8s.Deployment는 stateless 한 애플리케이션을 배포할 때 적합한 k8s 기능인데 데이터베이스는 대표적인 stateful 애플리케이션이기 때문이죠. stateful과 stateless 애플리케이션의 차이는 애플리케이션이 자체적으로 영구 데이터를 저장하느냐에 따라 구분됩니다.
자체적으로 영구 데이터를 저장하지 않는 stateless 애플리케이션은 각 요청을 독립적으로 처리하고, 이전까지 어떤 요청들이 있었는지가 다음 요청 결과에 영향을 주지 않습니다. 하지만 stateful 애플리케이션은 자체적으로 영구 데이터를 저장하며 동작합니다. 예를 들어서 신규 회원이 가입하는 경우, 새 회원의 정보가 DB에 저장이 되고 다음에 로그인과 같은 요청이 들어오면 저장된 회원의 정보를 기반으로 성공 또는 실패값을 반환하게 됩니다. stateful 애플리케이션을 K8s에 배포하고 싶을 때는 k8s.Statefulsets 라는 워크로드가 적절합니다. 하지만 Statefulsets도 모든 문제를 마법처럼 해결해 주지는 않았기 때문에 일단 PostgreSQL pod을 단 하나 띄워 두고 사용하기로 하였습니다.
그러나 이러한 구성만으로는 Runway 도입을 검토하는 고객의 안정성 요구사항을 충족하기에 부족했습니다. 고객사는 Runway의 운영 안정성과 고가용성(HA,High availabilty) 기반 시스템 구성을 핵심 요건으로 강조했습니다. HA는 말 그대로 어떤 시스템이 장애에 빠지지 않고 계속 사용 가능한 상태로 남아있을 수 있는 속성입니다. DB를 사용하는 시스템의 경우, DB에 장애가 발생하면 전체 시스템이 사용할 수 없는 상태에 빠지게 되기 때문에 DB를 가용한 상태로 유지하는 것이 매우 중요합니다. 현대의 많은 Database들은 DB의 복제본을 유지하고 메인 DB에 장애가 발생하는 경우 복제본을 자동으로 사용하게 만드는 형태로 HA를 지원하고 있습니다.
도와줘! Bitnami Helm Chart로 PostgreSQL-HA 구현!
Runway 개발팀은 bitnami/postgrsql-ha에서 제공하는 헬름 차트를 활용하여 PostgreSQL-HA cluster를 지원하기로 했습니다. 이 차트는 PostgreSQL, repmgrd, Pgpool-II를 조합하여 다음과 같은 형태로 PostgreSQL-HA cluster를 구성합니다.
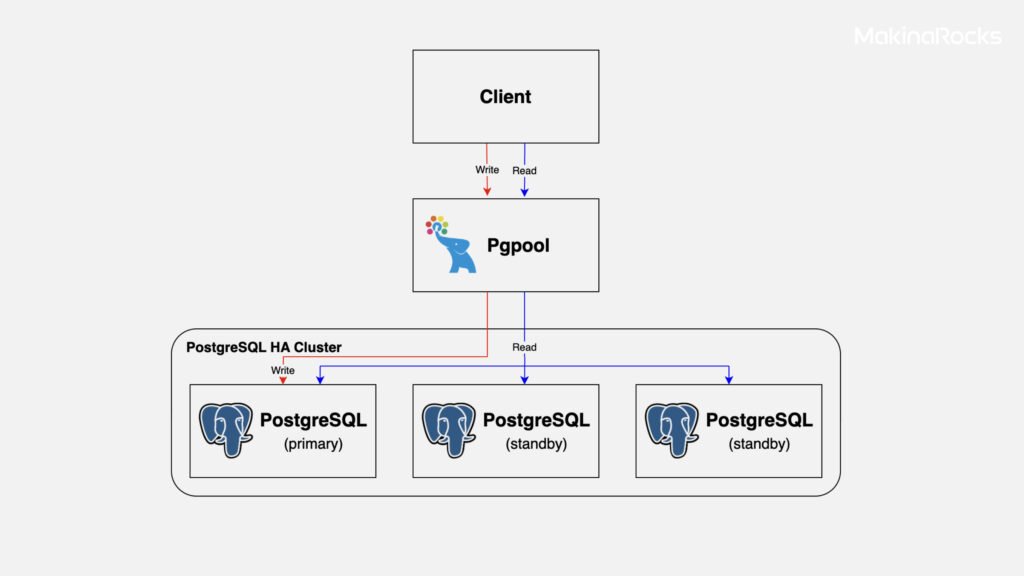
PostgreSQL-HA cluster 구성도
고가용성을 지원하기 위한 두 가지 핵심 기능은 복제(replication)와 장애 극복(failover)입니다. PostgreSQL은 이 두 기능을 통해 장애 상황에서도 데이터의 손실 없이 서비스를 지속할 수 있도록 설계되어 있습니다.
replication은 하나의 메인 데이터베이스(primary)의 데이터를 다른 복제본(standby)으로 실시간 혹은 실시간에 준하는 속도로 복제하는 기능입니다. PostgreSQL은 기본적으로 스트리밍 복제(streaming replication)라는 방식을 통해 이를 지원합니다. 스트리밍 복제는 primary 서버의 WAL(Write-Ahead Log)을 standby가 받아 반영함으로써 두 서버 데이터의 일관성을 유지합니다. 특히 이 구조는 비동기 및 동기 복제 모드 모두를 지원하며, 복제 지연을 최소화하면서도 데이터 일관성을 유지할 수 있도록 도와줍니다.
failover는 메인 DB에 장애가 발생했을 때 standby 서버 중 하나를 자동으로 새로운 primary로 승격(promotion)시켜 시스템이 중단 없이 계속 동작하도록 만드는 기능입니다. PostgreSQL 자체에는 failover 기능이 내장되어 있지 않지만, repmgrd과 같은 툴을 사용하여 이를 안정적으로 처리할 수 있습니다. repmgrd은 클러스터 내 노드 상태를 모니터링하고, primary 장애 시 적절한 standby를 자동으로 primary로 전환해 줍니다. 이 과정에서 Pgpool-II는 DB 클라이언트와 DB 서버 간의 연결을 중개하면서, 장애 상황에서도 연결을 자동으로 새로운 primary로 라우팅해 주는 역할을 수행합니다.
자 이제 누가 대장이지? Split Brain 발생!
이렇게 Runway 데이터베이스의 구성을 변환하여 Primary 서버에 문제가 생겼을 때, Standby 서버가 Primary 서버로 승격되면서 문제없이 Runway를 사용할 수 있는 것을 확인했습니다
하지만 복잡한 장애 시나리오에서 클러스터가 비정상적인 failover를 시도하면서 생기는 Split brain 이슈가 종종 발생하는 문제를 발견했습니다. Split Brain은 두 개 이상의 데이터베이스 노드가 서로를 primary로 인식하게 되면서 동시에 쓰기 작업을 처리하려고 할 때 발생하는 장애입니다. 이 상황이 발생하면 서로 다른 노드가 다른 데이터를 가지고 있을 수 있기 때문에, 데이터 일관성이 훼손될 수 있습니다. 단순히 장애가 발생하는 것을 넘어서, 복구 이후에도 어떤 데이터가 올바른지 판단하기 어려워지는 상황으로 이어질 수 있습니다.
Split Brain은 주로 다음과 같은 네트워크 단절(Network Partition) 상황에서 발생합니다.
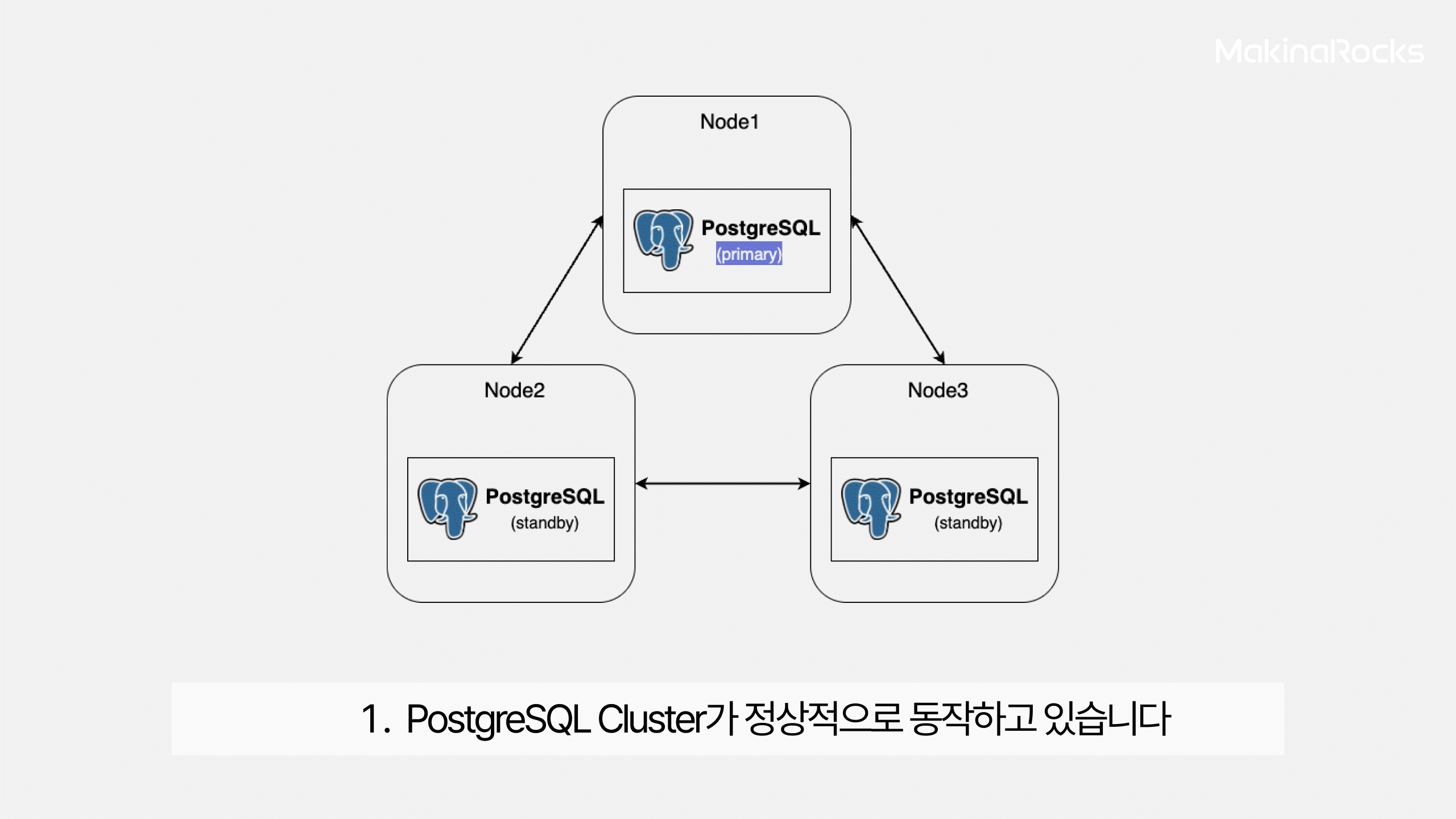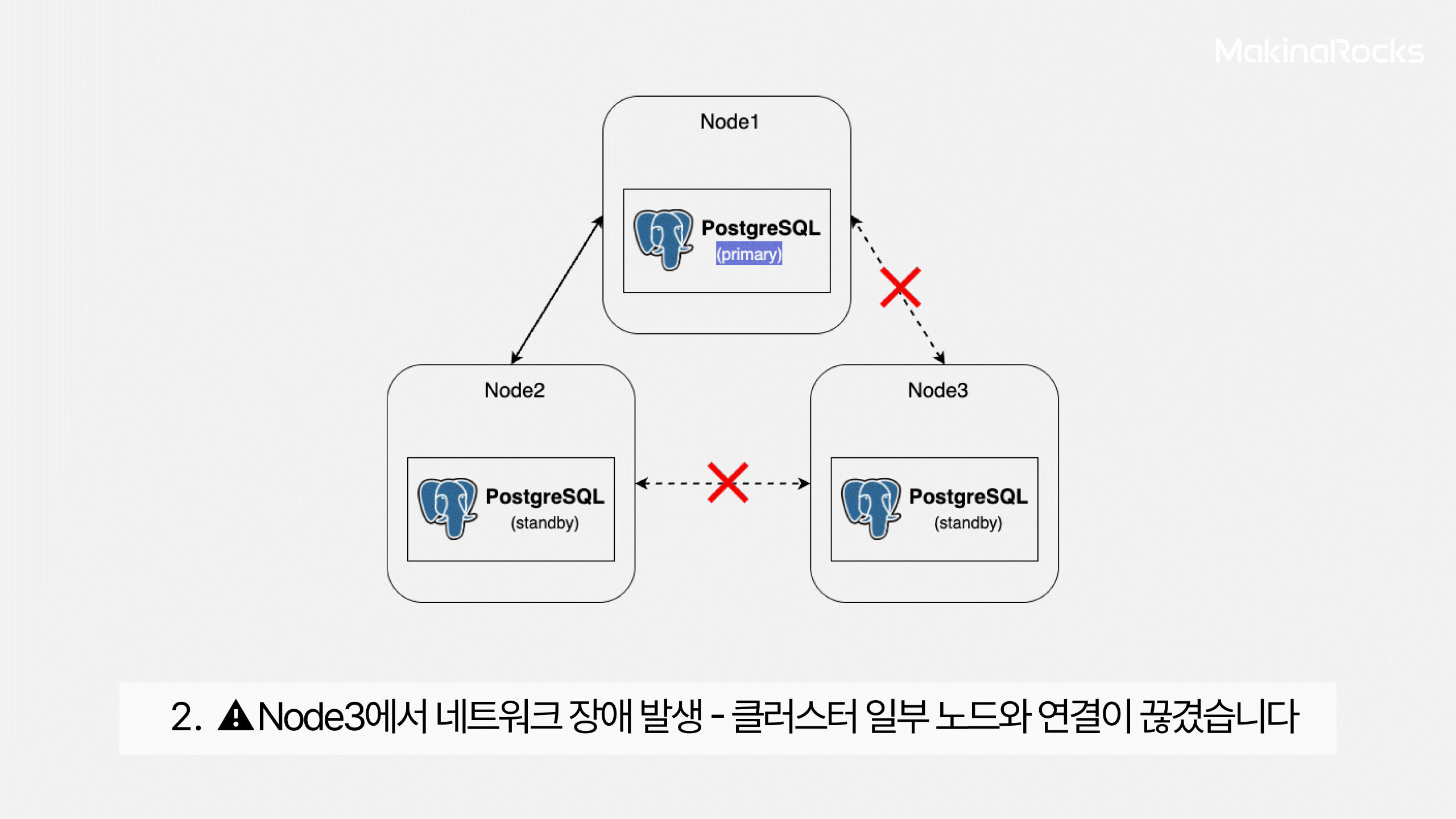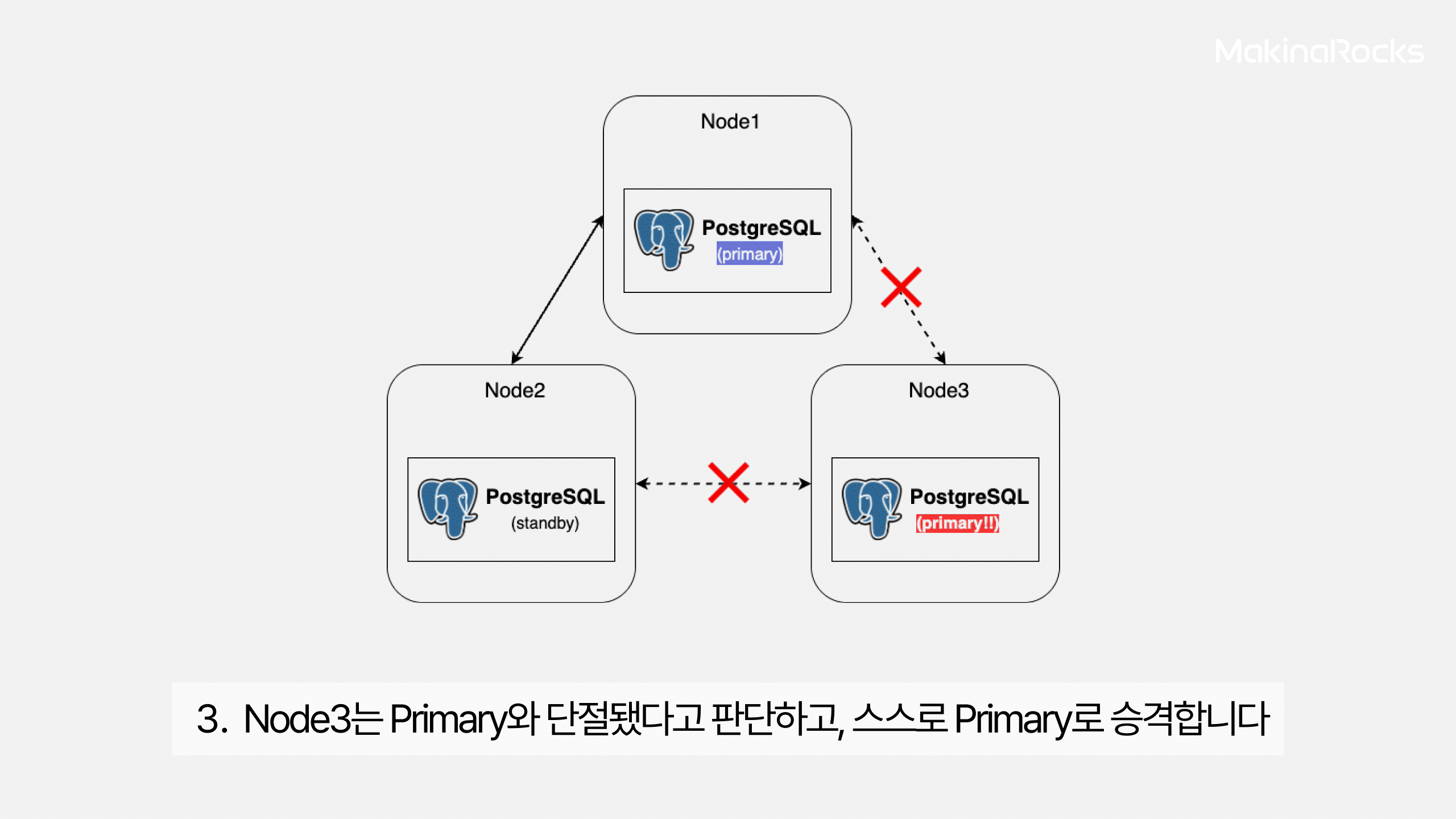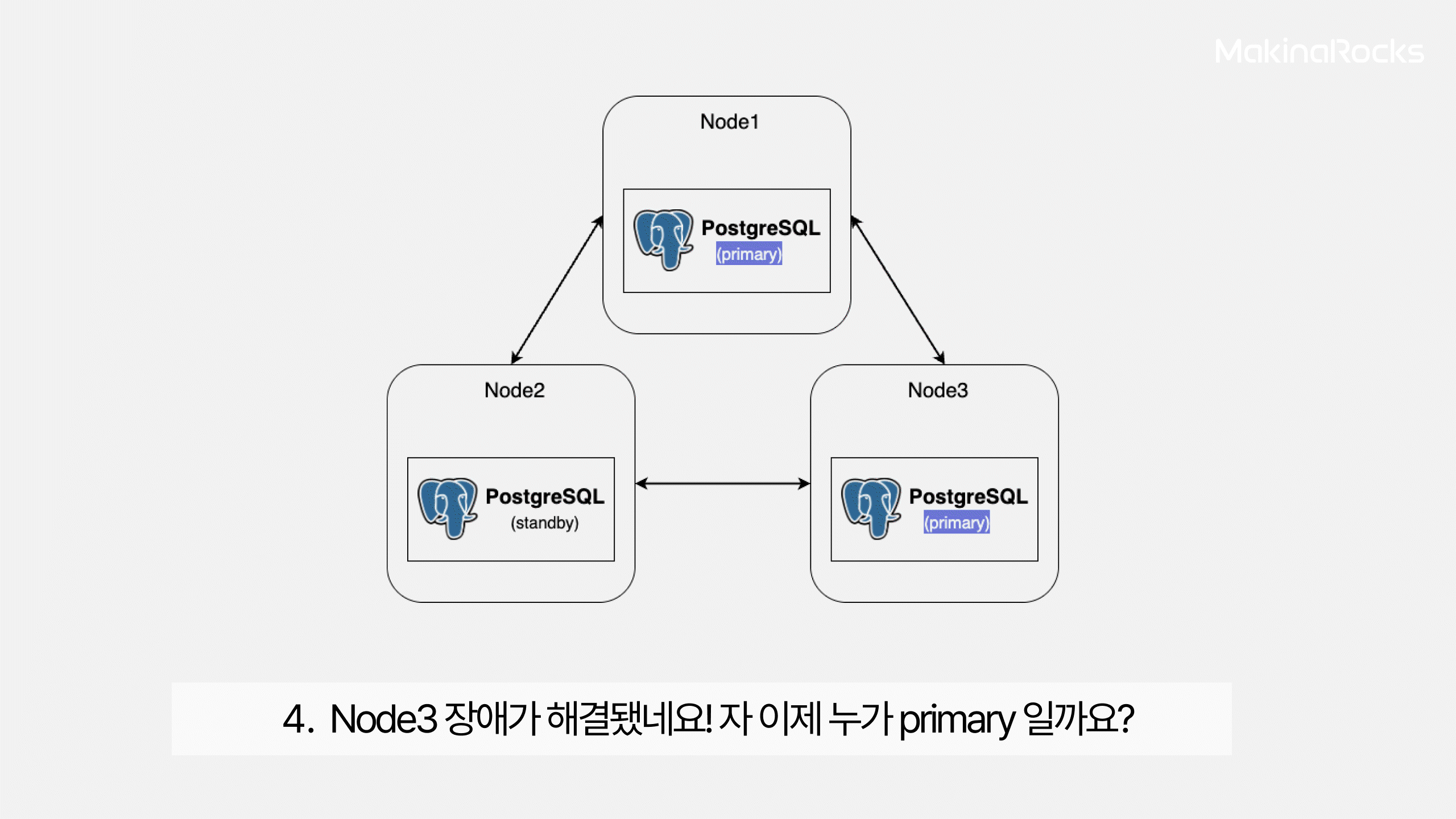
Split Brain이 발생하는 시나리오
이러한 문제를 해결하거나 완화하기 위해서 witness 서버를 활용하는 등 다양한 기능이 있었지만, 원인불명의 이슈로 계속하여 Split brain 이슈가 발생하였습니다. 결국 PostgreSQL HA cluster를 제공하기 위해서는 bitnami/postgrsql-ha에서 제공하는 헬름 차트가 아닌 다른 솔루션이 필요하다는 결론에 이르렀습니다.
Kubernetes 위에서 PostgreSQL cluster 구성을 도와주고 제공하는 솔루션은 다음과 같이 많은 것들이 있었습니다. 이 중에서 bitnami/postgresql-ha를 대체하기 위해서는 Standby 서버 구성을 지원하고, Failover 상황에서도 Split brain 이슈가 발생하지 않아야 합니다. 충분히 성숙했을 것으로 기대되는 cloudnative-pg, zalando/postgres-operator, CrunchyData/postgres-operator를 살펴보았을 때, 구체적인 방법은 다르지만 모두 원하는 기능을 제공하고 있는 것을 확인했습니다.
솔루션의 최종 결정을 위해 우리는 Runway가 외부 인터넷 통신이 불가능한 폐쇄망 환경에 설치되는 상황을 고려하였습니다. 폐쇄망은 제조업에 AI 서비스를 적용할 때 흔한 제약조건으로, 장애가 발생했을 때 빠르게 대응하기 힘들게 만듭니다. 이 점을 고려하여 가장 자동화 수준이 높은 cloudnative-pg(cnpg)를 bitnami/postgresql-ha의 대체 솔루션으로 선정하였습니다. cnpg는 Auto Pilot 수준의 자동 운영을 지원하고 있었기 때문에 폐쇄망 환경에서 장애가 발생해도 유연하게 자동으로 복구되어 더 안정적인 서비스를 제공할 수 있습니다.
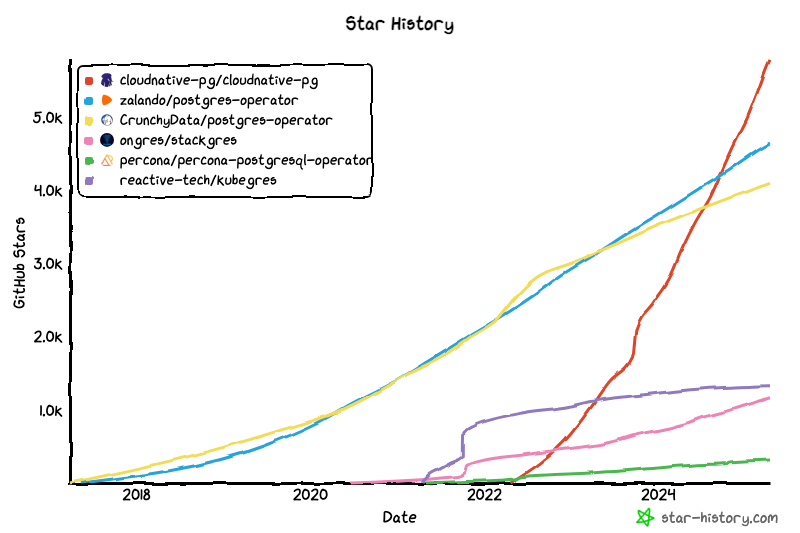
GitHub Star 기준으로 본 주요 PostgreSQL Operator 프로젝트들의 성장 추이
CNPG 기반 PostgreSQL Cluster에서 안정성을 되찾았습니다
기존에 채택한 bitnami/postgrsql-ha의 한계를 cnpg를 통해서 해결할 수 있는지 확인하기 위해 cnpg의 기능들을 확인해 보았습니다. 간략하게 소개하자면 다음과 같은 기능들을 가지고 있습니다.
Kubernetes API를 직접 사용
CloudNativePG는 Kubernetes에 PostgreSQL cluster를 배포할 수 있게 도와주는 Operator입니다. 내부적으로 Kubernetes API를 직접 사용하여 클러스터의 상태를 감지하고, 필요시 자동으로 복구 절차를 수행합니다. bitnami/postgrsql-ha를 통해서는 쉽게 해결할 수 없던 상황들을 cnpg는 어떻게 해결하고 있는지 분석해 보았습니다.
Failover 상황
- pg_isready를 사용해 PostgreSQL의 상태를 지속적으로 추적합니다.
- primary pod의 readiness probe가 실패하면, controller가 이를 감지하고 failover 모드에 진입합니다.
- 기존 primary pod는 종료됩니다.
- standby 노드들은 WAL receiver를 중단하고 대기 상태로 전환됩니다.
- 모든 receiver가 멈추면, 새로운 leader를 선출하고 해당 인스턴스를 새로운 primary로 지정합니다.
- 장애가 발생했던 기존 primary는 재시작되며, 자신이 더 이상 primary가 아님을 감지하고 standby로 전환됩니다.
Split-brain 방지 및 클러스터 복구 상황
저희를 가장 고통스럽게 했던 상황들은 클러스터에 장애가 발생했을 때, Standby 서버가 Primary 서버로 부적절하게 승격되거나, Standby 서버에 문제가 생겨 종료 후 다시 실행되었을 때 Primary 서버가 가지고 있는 데이터와 동기화를 해 주는 상황들이었습니다. 이러한 장애 상황 대응을 cnpg는 Operator에서 다음과 같이 처리하고 있습니다.
Primary 서버가 동작하고 있는 노드에 장애가 발생하여 Standby 서버를 Promote
PostgreSQL cluster에 장애가 발생하는 경우의 수는 정말 다양하고, cnpg operator는 최대한 많은 경우에 대해서 장애를 극복하기 위한 코드들을 가지고 있습니다. 아래의 코드는 그중에서 primary pod이 실행 중인 노드에 장애가 발생했을 때, 장애가 발생하지 않은 정상 노드에서 실행 중인 standby 서버를 primary 서버로 승격시키는 코드입니다. 실제로 cnpg operator에서 사용되고 있는 코드를 간추리고 한글 주석을 달았습니다. ‘Kubernates-Native 하게 PostgreSQL Cluster를 관리하는 건 이런 식이구나’라는 깨달음을 준 코드여서 소개합니다.
func (r *ClusterReconciler) setPrimaryOnSchedulableNode(
ctx context.Context,
cluster *apiv1.Cluster,
status postgres.PostgresqlStatusList,
primaryPod *postgres.PostgresqlStatus,
) (string, error) {
// Primary 서버가 동작하고 있는 노드가 아닌 다른 노드에 있는 Pod 리스트를 가져옵니다
podsOnOtherNodes := GetPodsNotOnPrimaryNode(status, primaryPod)
// Primary 서버로 승격하기 위한 후보를 선정합니다.
for _, candidate := range podsOnOtherNodes.Items {
// 후보는 사용 가능한 노드에서 동작하고 있어야 합니다
if status, _ := r.isNodeUnschedulableOrBeingDrained(ctx, candidate.Node); status {
continue
}
// 후보는 장애 없이 동작하고 있어야 합니다
if !utils.IsPodReady(*candidate.Pod) {
continue
}
// 후보는 현재 Primary 서버와 연결이 없어야 합니다
if !candidate.IsWalReceiverActive {
continue
}
// Primary 서버가 바뀌는 Switchover 상태로 업데이트 합니다.
if err := r.RegisterPhase(ctx, cluster, apiv1.PhaseSwitchover,
fmt.Sprintf("Switching over to %v, because primary instance "+
"was running on unschedulable node %v",
candidate.Pod.Name,
primaryPod.Node)); err != nil {
return "", err
}
// 이 후보를 cluster의 TargetPrimary로 등록합니다.
return candidate.Pod.Name, r.setPrimaryInstance(ctx, cluster, candidate.Pod.Name)
}
return "", nil
}
Standby 서버에 문제가 생겨 다시 생성하는 경우
Standby 서버에 문제가 발생하는 경우에는 cnpg operator는 어떤 작업들을 통해 장애를 극복할까요? Standby 서버가 다시 실행되었을 때 bitnami/postgrsql-ha의 기본 동작은 Primary 서버의 데이터를 “처음부터 모두 다” 다시 복사하여 가져오는 방식으로 동작합니다. DB의 크기가 증가하면 굉장히 큰 작업이 되기 때문에 정교하게 튜닝이 필요한 부분이었습니다. 이 상황을 아래와 같이 cnpg operator는 굉장히 독특한 방식으로 해결하고 있었습니다. 다수의 Standby 서버가 존재할 수 있지만, Primary와 Standby 서버가 하나씩 있는 상황에서 Standby 서버에 장애가 발생하면 다음과 같은 순서로 장애 극복 조치가 진행됩니다.
Standby 서버의 장애 극복 시나리오
다양한 시나리오 테스트와 분석을 거쳐, CNPG가 Bitnami PostgreSQL-HA보다 더 높은 안정성과 신뢰성을 갖춘 솔루션이라는 결론에 도달했습니다. 현재는 기술 검증을 마친 상태로 Runway 인프라에 적용하기 위한 마이그레이션 절차를 내부적으로 진행 중입니다.
Runway의 인프라는 한층 더 강화된 안정성 위에서 운영될 예정입니다. AI 플랫폼의 인프라 안정성이 고민이라면, 마키나락스의 선택과 개선 과정을 참고해 보셔도 좋습니다. 지금 Runway 데모를 통해 현장에서 신뢰받는 AI 플랫폼의 기반을 직접 확인해 보세요.








