
AIを企業の資産に転換する AI OS
Runwayは、単発的な知能化にとどまらず、知能を“システム化”することでAIを企業の中核資産へと転換する、エンタープライズ向けAI運用基盤です。








Runway が生み出す決定的な違い
GPUインフラのROIを最大化
追加のGPUを購入することなく、既存のリソースだけで、より多くのAIを運用します。
追加投資なしで使用効率を最大化
GPUを小数点単位で精密に分割し、学習では最大90%、推論では60~70%の実稼働率を実現します。
アイドル状態のGPUを自動回収
アイドル状態のGPUをリアルタイムで検知・回収し、放置されたリソースが発生しないよう、GPUが常に循環する仕組みで管理します。
重要タスクにGPUを優先配分
リアルタイムダッシュボードでGPUの利用状況を可視化し、リソースの独占を防止。重要業務へ優先的にGPUを割り当てます。
-

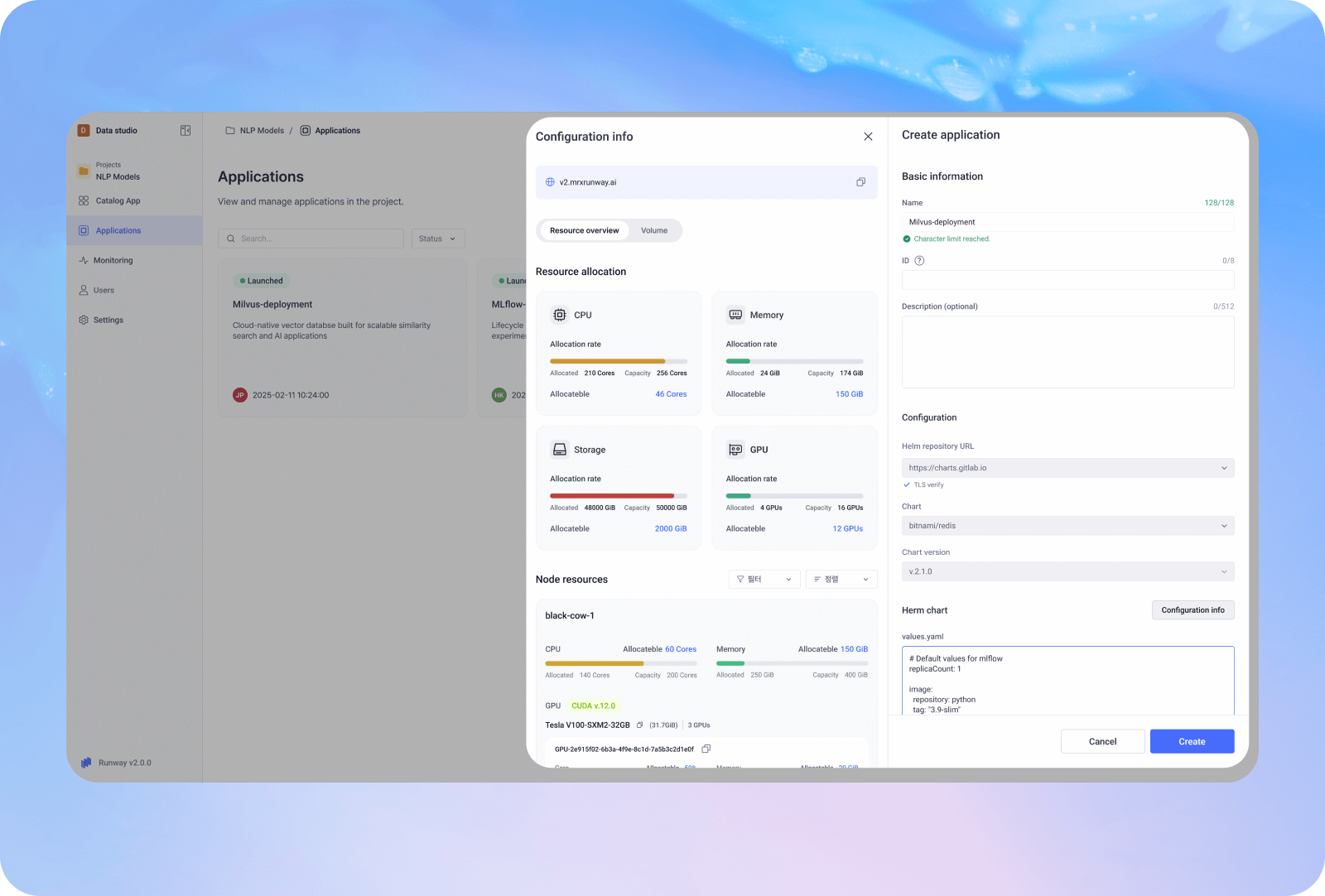
標準化された開発・運用環境
検証済みのオープンソースアプリケーションと統合開発環境をカタログ形式で提供し、個別インストールなしで、開発から運用・継続的改善までを一貫した標準プロセスで実行できます。
-
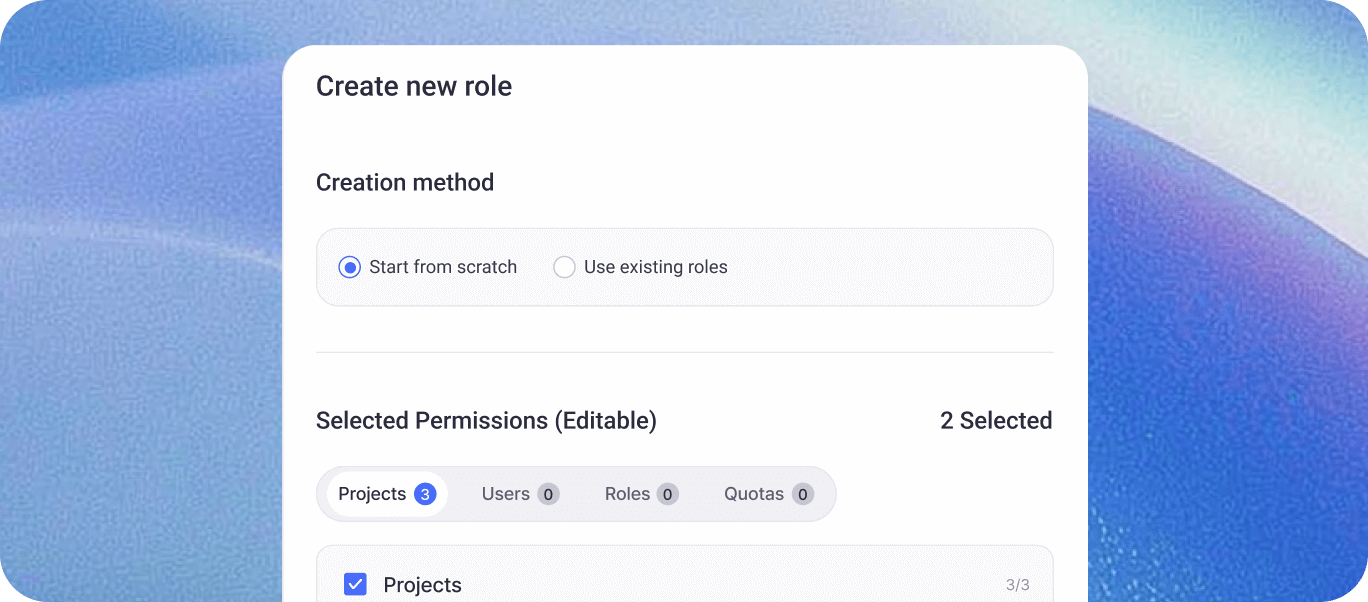
エンタープライズ級の統合ガバナンス
KeycloakベースのSSOにより、ロールベースアクセス制御(RBAC)を全レイヤーに適用し、あらゆる操作を監査ログで一元管理します。
-

閉域環境でも即時構築・実行
パッケージミラーリポジトリと自動化された持ち込み(搬入)プロセスにより、閉域ネットワーク環境においても外部依存なくAIを即時に実行できます。
1 / 1
ビジネスの限界を突破する、圧倒的な実行力
1 / 1
すべてのメンバーが、それぞれの役割に専念できる環境を提供します。
モデルの実験から学習、成果管理に至るまで、AI開発の全プロセスを一つのプラットフォーム上で実行します。
最も厳しい産業現場で実証された Runway
-
AIの専門知識が十分でなくても、閉域環境で即座に運用可能なAI基盤
閉域ネットワークや厳格なセキュリティ、インフラ制約のある環境下でも、専門人材に依存することなく、AI運用環境を迅速に構築・実行できました。
グローバル部品メーカー
-
1日700万件のトラフィックを、1.5秒以内で安定処理
大規模トラフィック環境においてもセキュリティ上の問題なく安定した性能を維持し、gRPCベースのアーキテクチャにより高速なレスポンスを実現しました。

1 / 1
Runway の多様な活用事例
さまざまな産業分野でAI運用の新たな基準を築いているRunwayの導入事例をご覧ください。
-

製造
設計・生産・品質・運用に至る全工程にわたるAI活用を、単一の運用基盤へと統合します。\n現場は変化により迅速に対応できるようになり、組織は複雑性を増やすことなく、AIを安定的に運用できます。
-

防衛
閉域ネットワークやエアギャップ環境においても、AIを即時に実行・統制できる運用基盤を提供します。\n現場では迅速な判断を可能にし、組織全体ではセキュリティとガバナンスを両立します。
-

公共
公共分野におけるセキュリティおよび制度要件を満たしながら、AIを独立して開発・運用できる体制を構築します。\n外部依存に頼らない、持続可能な公共AI運用を実現します。
-

金融
企画・開発・リスク管理・運用に至る全プロセスのAI活用を、単一の運用基盤で統合管理します。\n金融サービスの迅速な拡張を実現しながら、ガバナンスと安定性を一貫して維持します。
1 / 1
The Operating System for Enterprise AI
AIプロジェクトを“成功するビジネス資産”へと変えるエンジン、Runway。
Runwayで、AI成功の可能性を最大化してください。
