

마키나락스 의 AI 플랫폼 Runway는 AI 모델의 개발부터 배포, 운영까지 전 과정을 지원합니다. 특히 Production 환경에서 모델을 안정적으로 서빙하기 위한 다양한 기능을 제공합니다. 그중 핵심 기능 중 하나는 추론 서비스의 Autoscaling입니다.
실제 운영 환경에서는 서비스의 요청량이 실시간으로 변동되기 때문에, 이에 맞게 컴퓨팅 자원을 동적으로 조절하여 안정적인 서비스를 제공하면서도 효율적으로 비용을 관리하는 Autoscaling이 필수적입니다. 사용량이 많을 때는 자원을 늘려(Scale-Out) 안정적인 서비스를 제공하고, 사용량이 적을 때는 자원을 줄여(Scale-In) 불필요한 자원 낭비로 추가적인 비용이 발생하는 것을 막아야 합니다.
자원 관리의 사각지대: Autoscaling
Runway는 사용자가 논리적인 자원 관리 단위인 Workspace와 Project 레벨에서 정해진 자원을 할당받아 사용하도록 설계되었습니다. 각 워크스페이스와 프로젝트는 관리자에 의해 CPU, Memory, GPU, Disk와 같은 자원의 한도가 정해져 있으며, 사용자는 이 한도 내에서 개발용 인스턴스, 추론 서비스 등 필요한 리소스를 생성하고 운영할 수 있습니다. 추가적인 자원이 필요한 경우 관리자에게 요청하여 추가 할당을 받은 후 사용할 수 있습니다.
Runway 초기 버전에서는 사용자가 리소스를 생성하거나 수정하는 시점에만 Workspace 및 Project의 자원 한도를 확인했습니다. 서비스 요청량 변화에 따라 추론 서비스의 replica 수가 동적으로 조절되는 Autoscaling 상황에서는 자원 한도 검증이 이루어지지 않았습니다. 예를 들어, 갑자기 많은 요청이 몰려 Autoscaling이 트리거 되면, 해당 서비스가 Workspace에 할당된 자원을 초과하여 Replica를 생성할 수 있었습니다. 이로 인해 예상치 못한 비용 문제나 Multi-tenant 클러스터에서 다른 Workspace의 자원을 침해할 수 있는 문제들이 발생할 수 있었습니다.
그동안 Autoscale 시의 max_autoscale 값을 보수적으로 제한하고 있었기에 큰 이슈로 번지지는 않았지만, 향후 잠재적인 위험 요소가 될 수 있었습니다. 안정적인 서비스 운영과 비용 최적화를 위한 Autoscaling을 위해 마키나락스가 했던 고민들과 그 해결 과정을 공유드리고자 합니다.
기술적 배경: Kserve, Knative Serving, HPA
Runway의 추론 서비스는 안정적이고 자원 효율적인 서빙을 위해, 모델의 특징에 따라 크게 KServe Inference Service와 Knative Service 기반으로 Kubernetes 클러스터에 배포됩니다. KServe Inference Service는 Knative Service를 기반으로 하는 Custom Resource이므로, 두 종류의 서비스 모두 knative/autoscaler라는 컴포넌트가 Autoscaling 과정을 동일하게 관리합니다.
Knative Service의 Autoscaling은 크게 두 가지 방식으로 이루어집니다.
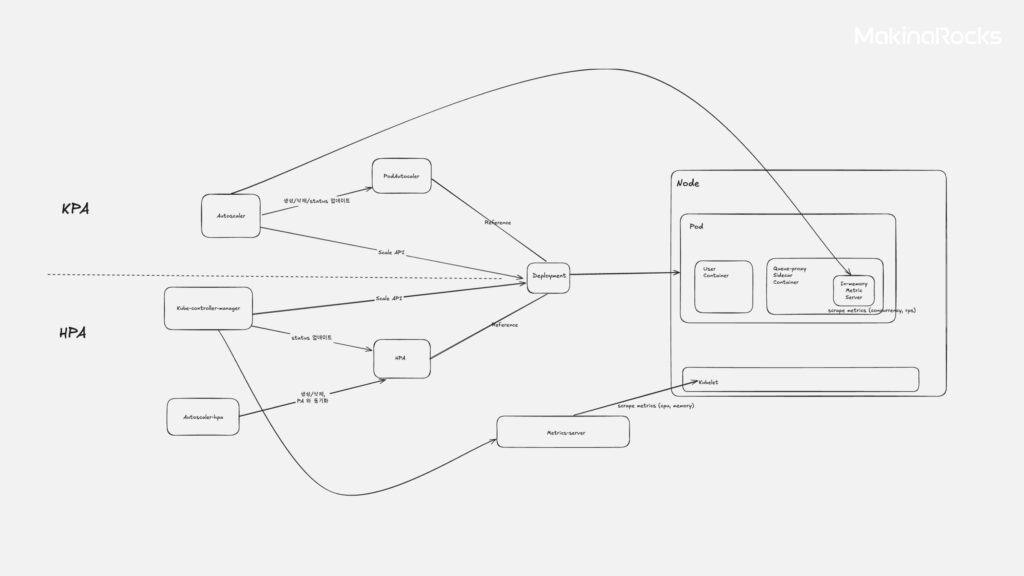
Knative Service의 Autoscaling 방식
-
KPA (Knative Pod Autoscaler): Knative의 기본 Autoscaling 방식으로, 주로 서비스 관점의 메트릭(RPS - 초당 요청 수, Concurrency - 동시 처리 요청 수)을 사용하여 Scaling합니다.
- 동작 구조: 각 Pod에 주입되는
queue-proxy사이드카 컨테이너가 메트릭을 수집하여autoscaler에 전달하면,autoscaler가 메트릭과 설정값을 기반으로 목표 Scale 값을 계산하고 직접 Deployment Update API를 수행합니다. Scale-to-zero 기능을 지원합니다.
- 동작 구조: 각 Pod에 주입되는
-
HPA (Horizontal Pod Autoscaler): Kubernetes의 기본 Autoscaler 로, 자원 사용량 관점의 메트릭(CPU, Memory 사용률)을 사용하여 Scaling합니다. Knative Service 에서는
knative/autoscaler-hpa가 HPA 에게 Autoscaling 관련 역할을 Delegate 하는 형태로 통합되어있습니다.- 동작 구조:
metrics-server가 모든 Pod의 메트릭을 수집하여kube-controller-manager에 전달하면,kube-controller-manager가 메트릭과 설정값을 기반으로 목표 Scale 값을 계산하고 Deployment Scale API를 수행합니다. 이때, Pod에 설정된 requests 값 대비 상대적인 사용률을 기준으로 판단합니다. Scale-to-zero는 지원하지 않으며 , HPA 로직은kube-controller-manager가 관리합니다. HPA는 기본적으로 15초마다(-horizontal-pod-autoscaler-sync-period) 목표 Scale 값을 재계산하고 , Scale-down 시에는 기본 5분의 안정화 기간(-horizontal-pod-autoscaler-downscale-stabilization)을 가집니다.
- 동작 구조:
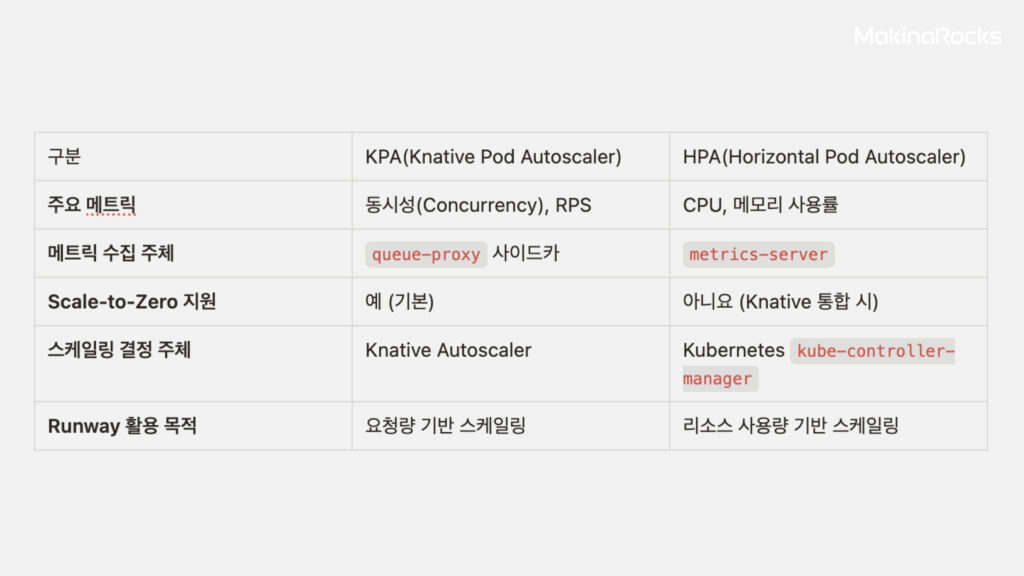
KPA vs HPA 비교표
Runway는 서비스 및 고객사 특성에 따라 설치/업그레이드 시, KPA 또는 HPA를 선택적으로 활용하여 적절한 Autoscaling 전략을 설정할 수 있습니다. 따라서 Runway의 Workspace 자원 한도를 강제하는 방안은 KPA와 HPA 양쪽에서 발생하는 Autoscaling 상황을 모두 처리할 수 있어야 했습니다.
해결 방안 탐색 여정
Autoscaling 과정에서 Runway Workspace 자원 한도를 검증하고 강제하기 위해 여러 기술적 접근 방안을 검토했습니다. 각 방안은 기술적 요구사항의 만족도, 구현 복잡도와 유지보수성, 잠재적 부작용을 기준으로 평가했습니다.
사이드카 컨테이너 활용 (예: Istio EnvoyFilter)
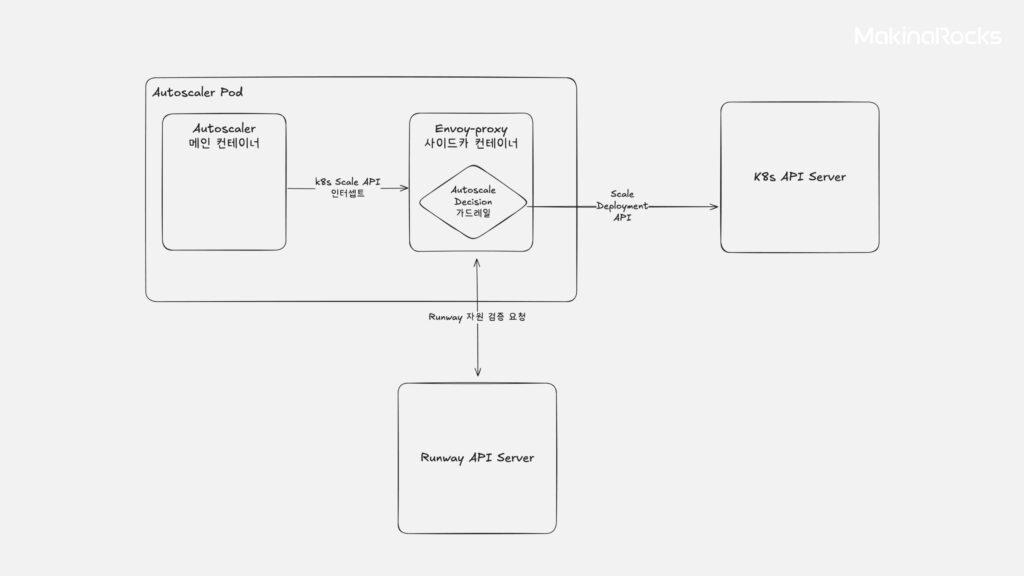
사이드카 컨테이너 활용
- 개념: Autoscaling Action을 취하는 Deployment(Knative Autoscaler, kube-controller-manager)에 Envoy Proxy와 같은 사이드카 컨테이너를 주입하여 Deployment의 Replica 수를 변경하는 Kubernetes API 아웃바운드 요청을 가로챕니다. 이후 요청 정보를 추출하여 Runway API로 쿼터를 검증한 뒤, 요청을 허용/수정/거부합니다.
- 평가: Lua 스크립트 작성 등 구현 복잡성이 높아 우선순위를 낮췄습니다.
- 개념: Kubernetes Namespace에 대해 CPU, Memory 등 자원의 총량을 제한하는 Kubernetes 네이티브 기능입니다.
- 평가: Runway는 Namespace에 종속되지 않는 워크로드도 지원하며, 추후 Project 또는 User Role 레벨 등 다양한 계층으로 자원 할당 정책이 추가될 수 있음을 고려할 때 확장성이 부족하다고 판단하여 검토 대상에서 제외했습니다.
- 개념: Autoscaler의 목표 Scale 값 결정 이후, Deployment의 Scale 값 Update 요청이 발생하면 Pod의 생성/삭제 요청이 발생합니다. 이때, 해당 Pod는 별도의 커스텀 Scheduler의 스케줄 정책을 따르도록 하며, Scheduler는 Runway API로 자원 할당 검증 과정을 수행하여 Pod 생성을 허용/수정/거부합니다.
- 평가: Autoscaler에서 결정된 목표 Scale 값으로 Deployment의 Update 요청이 발생하지만, 이후 Pod 생성을 거부하게 되면 Autoscaler의 Reconciler는 목표 Scale과 실제 Scale이 다르다고 판단하여 계속해서 Kubernetes API 서버에 Deployment Update 요청을 보내게 됩니다. 이는 Kubernetes API 서버와 Autoscaler 모두에게 불필요한 부하를 생성하게 되므로, 성능 저하 등의 부작용이 발생할 수 있다고 판단하여 우선순위를 낮췄습니다.
쿠버네티스 어드미션 컨트롤 (Admission Control) - 웹훅(Webhook):
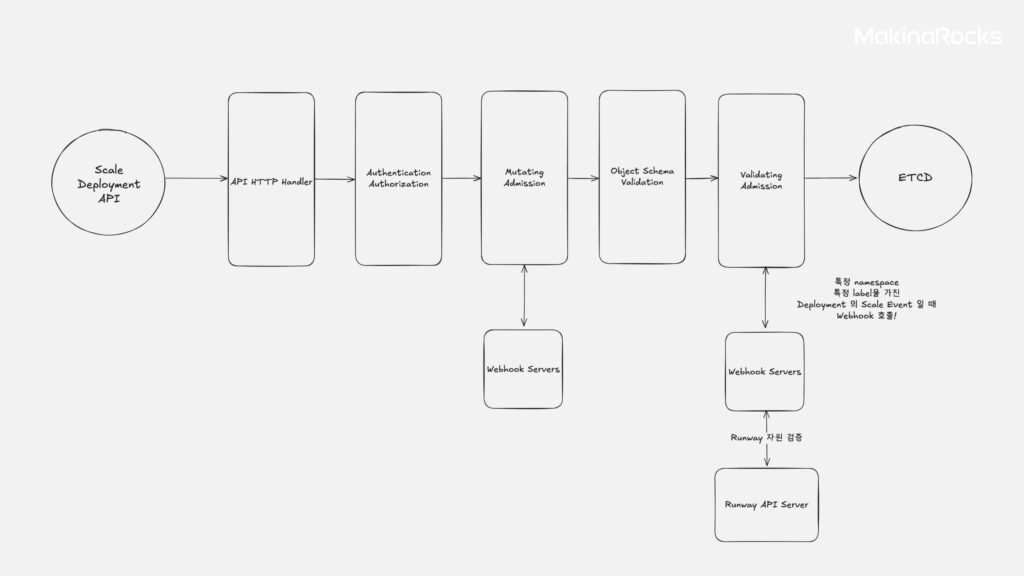
k8n 어드미션 컨트롤
- 개념: Kubernetes API 서버로 들어오는 요청(예: Deployment scale 업데이트)을 최종 저장(etcd) 전에 가로채어 검증하거나 수정하는 메커니즘입니다.
ValidatingWebhookConfiguration또는MutatingWebhookConfiguration으로 특정 조건의 요청을 외부 Webhook 서버로 보내고, Webhook 서버는 Runway API 호출로 검증 후 요청을 허용/거부하거나 수정하는 방식을 사용할 수 있습니다. - 평가: Scheduler Plugin과 유사하게 단순 거부 시 부하 문제가 있을 수 있으나, Deployment Scale 업데이트 시점에 더 일찍 개입할 수 있습니다.(Fail Fast)
objectSelector등으로 Webhook 호출 대상을 명확히 지정하면 부하를 줄일 수 있고 , 표준 Kubernetes 확장 기능으로 구현 복잡성을 줄일 수 있어 POC(Proof of Concept) 대상으로 선정했습니다.
Knative Autoscaler Customization:
- 개념: Knative
autoscaler컴포넌트의 소스 코드를 수정하여 목표 Scale 값 계산 로직에 Runway API 호출과 쿼터 검증을 직접 추가합니다. 수정된 코드로 커스텀 이미지를 빌드해 배포합니다. - 평가: Autoscaling 로직에 직접 쿼터 검증을 통합할 수 있는 장점이 있습니다. 다만 Knative 버전 업그레이드 시 코드 병합과 이미지 관리의 유지보수 부담이 크고, Runway API 호출 빈도가 매우 높아질 수 있습니다. 그럼에도 초기 개발 속도에 이점이 크고 변경의 자유도가 높다고 판단하여 POC 대상으로 선정했습니다.
Customize 가 필요한 로직을 간단하게 요약했습니다.
func (ks *scaler) applyScale(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler, desiredScale int32, ps *autoscalingv1alpha1.PodScalable) error {
logger := logging.FromContext(ctx)
gvr, name, err := resources.ScaleResourceArguments(pa.Spec.ScaleTargetRef)
if err != nil {
return err
}
// 중략...
// Deployment Scale을 수정하는 Patch API 가 호출됩니다.
// 따라서 이 함수의 호출 전에 desiredScale 값을 customize 하여 계산하는 로직을 추가할 수 있습니다.
_, err = ks.dynamicClient.Resource(*gvr).Namespace(pa.Namespace).Patch(ctx, ps.Name, types.JSONPatchType, patchBytes, metav1.PatchOptions{})
if err != nil {
return fmt.Errorf("failed to apply scale %d to scale target %s: %w", desiredScale, name, err)
}
logger.Debug("Successfully scaled to ", desiredScale)
return nil
}
위의 desired Scale 값은 다음과 같은 로직에 의해 결정됩니다.
func (a *autoscaler) Scale(logger *zap.SugaredLogger, now time.Time) ScaleResult {
// 1. 현재 scale 상태 조회
// 2. 정해진 기준 metric 을 직접 수집
// 3. scale limit 계산 (max scale up, max scale down)
// 4. metric 을 바탕으로 desired scale 1차 계산
// 5. scale limit 으로 clamp 수행
// 6. activation 상황, panic mode 등 처리
// 최종 desired scale 값 결정 후 반환
return ScaleResult{
DesiredPodCount:desiredPodCount,
}
}
Kubernetes Admission Control Webhook을 선택한 이유
이렇게 선정된 두 가지 방안으로 실제 구현과 동작 검증을 검토하는 POC를 진행한 결과, Kubernetes Admission Control Webhook 방식이 확장성, 유지보수성 등에서 더 적절한 해결책이라고 판단하여 최종적으로 결정하였습니다.
선택의 가장 큰 이유는 확장성이었습니다. Autoscaling을 수행하는 Operator를 커스터마이징하는 방안은 KPA를 위해서는 knative/autoscaler를, HPA를 위해서는 kube-controller-manager를 커스터마이징해야 합니다. 또한, 추후 고도화된 메트릭을 기준으로 Autoscaling을 trigger하기 위해 검토 중이었던 KEDA 방식을 위해서는 또 keda-controller를 커스터마이징해야 하므로 확장성이 떨어진다고 판단했습니다. (하지만, 현재는 더 복잡하고 다양한 형태의 metric 으로 Autoscaling하고싶다는 기능적 요구사항이 추가됨에 따라서, 유연한 Autoscaling 을 지원하기 위해서 KEDA를 다시 검토 중에 있습니다.)
하지만 Kubernetes Admission Control 과정에 개입하는 방식은 모든 Custom Resource에 대해서 동일하게 적용할 수 있기에, 추후 소프트웨어 요구사항 명세가 변경되는 상황에서도 유연하게 대처(resilient)할 수 있다는 강점이 있습니다.
구현은 쉬웠어요
Admission Control 과정의 Webhook 구현은 비교적 간단합니다.
-
-
ValidatingWebhookConfiguration 정의: 쿠버네티스 클러스터에
ValidatingWebhookConfiguration리소스를 배포합니다. 예를 들어, 이번 이슈에서는 다음과 같은 정의를 포함하여 리소스 명세를 작성합니다.-
어떤 Event가 발생하면:
deployments/scale의UPDATEEvent
rules:
- operations: ["UPDATE"]
apiGroups: ["apps"]
apiVersions: ["v1"]
resources: ["deployments/scale"] -
어떤 Webhook 서버(clientConfig)의 어떤 API를 호출할지: 구현할 Webhook 서버의
/validate API호출service:
name: {{ include "hpa-validator.fullname" . }}
namespace: {{ .Release.Namespace }}
path: "/validate"
port: {{ .Values.service.port }}clientConfig:
-
그리고 Webhook 서버 연결 실패 시 어떻게 처리할지: 실패(
Fail)로 설정
failurePolicy: Fail -
이 과정에서
namespaceSelector와objectSelector를 사용해 의도된 특정 Event에 대해서만 Webhook이 호출되도록 범위를 제한합니다.
namespaceSelector:
matchLabels:
test.makinarocks.ai: runway-sample
-
어떤 Event가 발생하면:
-
Webhook 서버 개발 및 배포: 쿠버네티스 클러스터 내에
AdmissionReview요청을 처리하는 Webhook 서버를 개발하고 배포합니다. 이 서버는 다음 로직을 수행합니다:- 요청 수신 및 파싱:
AdmissionReview요청에서 Deployment 정보(특히spec.replicas값)와 워크스페이스 식별 정보를 추출합니다. - Runway API 호출: 추출된 정보로 Runway 백엔드의 자원 검증 API를 호출하여 워크스페이스의 쿼터 상태와 Replica 변경 가능 여부를 확인합니다.
-
응답 생성: Runway API는 단순한 가능/불가능이 아닌, 현재 쿼터 내에서 허용 가능한 최대 Replica 수(
maxAvailableScale)를 계산하여 반환합니다. Webhook 서버는 오토스케일러가 결정한 Replica 수(desiredScale)와 이maxAvailableScale값을 비교합니다.- 결정된 Replica 수가
maxAvailableScale이하면 요청을 그대로 허용(allowed: true)합니다. - 결정된 Replica 수가
maxAvailableScale을 초과하면, 요청을 거부합니다. 초기 구현 단계에서는min(maxAvailableScale, desiredScale)로 scale 을 직접 수정하여, patch body 를 generate 하는MutatingWebhookConfiguration보다는 조금 더 보수적으로 사용자에게 “이런 이유로 autoscale 이 실패했습니다”를 안내해주는 형태로 진행하였습니다. 직접 값 수정을 진행하면, k8s level 의 available resource 값이 실시간으로 달라질 수 있기에 race condition 을 고려해야 한다는 문제를 해결하는 것은 우선순위가 낮다고 판단했습니다.
- 결정된 Replica 수가
- 응답 반환: 구성된
AdmissionReview응답 객체를 반환하면, 남은 admission control 과정을 이어가게 됩니다. - 해당 로직을 담고 있는 Webhook Server 의 코드의 간략한 버전은 다음과 같습니다.
- 요청 수신 및 파싱:
-
ValidatingWebhookConfiguration 정의: 쿠버네티스 클러스터에
package main
import (
"io"
"log"
"net/http"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/serializer"
"k8s.io/apimachinery/pkg/util/json"
"strings"
admissionv1 "k8s.io/api/admission/v1"
appsv1 "k8s.io/api/apps/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
var (
scheme = runtime.NewScheme()
codecs = serializer.NewCodecFactory(scheme)
)
// Webhook Server 정의
func main() {
// 라우트 정의
http.HandleFunc("/validate", serveValidate)
err := http.ListenAndServeTLS(":443", "/tls/server.crt", "/tls/server.key", nil)
if err != nil {
log.Fatalf("Failed to start webhook server: %v", err)
}
}
// http handler 정의
func serveValidate(w http.ResponseWriter, r *http.Request) {
body, err := io.ReadAll(r.Body)
if err != nil {
log.Printf("Could not read request body: %v", err)
http.Error(w, "could not read request body", http.StatusBadRequest)
return
}
// admission review request 검증 시작
var admissionReview admissionv1.AdmissionReview
_, _, err = codecs.UniversalDeserializer().Decode(body, nil, &admissionReview)
if err != nil {
log.Printf("Could not decode request: %v", err)
http.Error(w, "could not decode request", http.StatusBadRequest)
return
}
// 검증해야 하는 request 인지 필터링...
request := admissionReview.Request
if !(request.UserInfo.Username == "system:serviceaccount:knative-serving:controller" && strings.HasPrefix(request.UserInfo.Extra["authentication.kubernetes.io/pod-name"][0], "autoscaler")) {
log.Printf("Request not from autoscaler, allowing request")
admissionResponse := admissionv1.AdmissionResponse{
UID: request.UID,
Allowed: true,
}
admissionReview.Response = &admissionResponse
respBytes, err := json.Marshal(admissionReview)
if err != nil {
log.Printf("Could not encode response: %v", err)
http.Error(w, "could not encode response", http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(respBytes)
log.Println("Handled admission review request successfully")
return
}
// 검증해야 하는 admission request 요청만, Runway 의 자원 관리 로직을 수행하도록 한다.
var requestDeployment appsv1.Deployment
if err := json.Unmarshal(request.Object.Raw, &requestDeployment); err != nil {
log.Printf("Could not unmarshal deployment: %v", err)
http.Error(w, "could not unmarshal deployment", http.StatusBadRequest)
return
}
admissionResponse := admissionv1.AdmissionResponse{
UID: request.UID,
}
// 예시 필터링 로직: test:test label 이 존재하는지 확인
if value, exists := requestDeployment.Labels["test"]; !exists || value != "test" {
log.Printf("Label test:test not found, allowing request")
admissionResponse.Allowed = true
admissionReview.Response = &admissionResponse
respBytes, err := json.Marshal(admissionReview)
if err != nil {
log.Printf("Could not encode response: %v", err)
http.Error(w, "could not encode response", http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(respBytes)
log.Println("Handled admission review request successfully")
return
}
if requestDeployment.Spec.Replicas != nil {
log.Printf("Desired Replicas: %d", *requestDeployment.Spec.Replicas)
} else {
log.Printf("Desired Replicas: <nil>")
}
isRevisionOwner := false
for _, ownerRef := range requestDeployment.ObjectMeta.OwnerReferences {
if ownerRef.Kind == "Revision" {
isRevisionOwner = true
break
}
}
// 검증해야 하는 admission review 요청이면, Runway API 를 호출하여 자원 검증 로직 수행
if isRevisionOwner && !validateReplicas(requestDeployment) {
log.Println("Replica validation failed by external API")
admissionResponse.Allowed = false
admissionResponse.Result = &metav1.Status{
Message: "Replica validation failed by external API",
Reason: metav1.StatusReasonUnauthorized,
}
} else {
admissionResponse.Allowed = true
}
// 최종 admission review response 반환
admissionReview.Response = &admissionResponse
respBytes, err := json.Marshal(admissionReview)
if err != nil {
log.Printf("Could not encode response: %v", err)
http.Error(w, "could not encode response", http.StatusInternalServerError)
return
}
log.Printf("AdmissionReview Response JSON: %s", string(respBytes))
w.Header().Set("Content-Type", "application/json")
w.Write(respBytes)
log.Println("Handled admission review request successfully")
}
func validateReplicas(deployment appsv1.Deployment) bool {
// Mocking external API call
// 외부 API 호출 및 검증 로직 구현
log.Println("Request to RUNWAY API HERE")
// 외부 API 검증 실패 시 false, 허용 시 true 반환
// 필요 시, max-available 값을 반환
return false
}
3. Runway Backend Server API 개발: Runway API는 단순한 가능/불가능이 아닌, 현재 쿼터 내에서 허용 가능한 최대 Replica 수(maxAvailableScale)를 계산하여 반환합니다. 이 방식으로 오토스케일러의 의도 (스케일링)와 Runway의 정책(자원 한도)을 효과적으로 조화시키면서, 단순 거부로 인한 불필요한 시스템 부하도 방지할 수 있었습니다.
구현 과정에서 든 고민들
구현 자체는 비교적 간단했지만, 구현 과정에서 여러가지 고민이 뒤따랐습니다. 구현 과정에서 마주한 고민들을 공유해보려 합니다.
-
Runway 자원 한도를 고려한 Desired Scale 값을 최종 결정하는 주체:
- Runway 백엔드는 정책에 따라 Capacity 기반의
max-available scale을 결정합니다. - Validation 로직은 Runway API 서버가 수행하지만, Autoscaling할 값을 결정하고 실제로 Update를 수행하는 주체는 Autoscaler라고 생각했습니다. Autoscaler가 Kubernetes API 서버에게 참고용으로 노드별 Capacity를 물어보듯, Runway API 서버에게도 Capacity를 물어보고 그 결과를 바탕으로 최종 목표 Scale 값을 결정하는 역할(예:
min(desired_scale_from_autoscaler, available_scale_from_workspace_cap))을 담당하는 것이 이상적이라고 판단했습니다. (이번 구현에서는 Webhook에서 거부하는 방식으로 단순화했습니다.)
- Runway 백엔드는 정책에 따라 Capacity 기반의
- Lifecycle: Runway 백엔드와 연동하는 컴포넌트(Webhook 서버)는 Runway Namespace에 두는 것이 적절하다고 판단했습니다. 만약 Runway 백엔드가 사라지면 Webhook은 호출할 URL이 무효화되므로 스스로도 할 일이 없어지는 것이라 생각하여, Runway 백엔드의 Lifecycle에 종속적이라고 보았습니다.
- KPA/HPA 동시 지원: Webhook 방식은 Deployment의
spec.replicas변경을 가로채므로, 스케일링 주체와 관계없이 동일한 메커니즘으로 쿼터 검증이 가능합니다. 또한 AdmissionReview 의 Request 로 스케일링을 요청한 주체에 대한 정보가 들어오기 때문에, 주체에 따라 서로 다른 Scaling 정책을 가져가는 것도 용이합니다. - Scale-to-Zero 처리: Knative의
activator가 Serverless 서비스를 깨우기 위해 Replica 수를 0에서 1로 변경하는 요청도 Webhook을 통해 쿼터 검증을 수행하면, Autoscaler를 커스터마이징하는 방안과 달리 한 번에 처리 가능했습니다. 만약 Autoscaler를 커스터마이징하는 방안을 실행했다면,activator또한 직접 커스터마이징해야 했을 것입니다. - 무중단 서비스: Scale-in/Scale-out 시, 배포 전략(strategy)을
RollingUpdate등으로 지정하더라도 Pod의 상태(Status)를 정확하게 표기하지 않는다면 트래픽이 유실되는 상황이 발생합니다. 예를 들어, Scale-out 상황에서 실제 컨테이너는 트래픽을 받을 준비가 되지 않았지만, 컨테이너와 Pod의 상태가Running으로 표기되면 해당 Replica Pod로 들어간 트래픽은 유실될 수 있습니다. 실제로 Knative Service로 생성되는 메인 컨테이너는 이미지에 따라 컨테이너의 Readiness가 실제 Running 상태를 의미하지 않는 경우가 존재했습니다. 따라서 Pod의livenessProbe,readinessProbe,startupProbe설정과 충분한 정상 종료(Graceful Shutdown) 시간 확보로 Autoscaling 상황에서 트래픽 유실과 서비스 중단을 방지하였습니다. -
성능 및 부하 관리:
- Webhook 범위 제한:
ValidatingWebhookConfiguration의namespaceSelector, objectSelector로 의도한 Event 에만 Webhook이 호출되도록 하여 서버 부하를 최소화했습니다. - Webhook Server 최적화: HPA의 기본 동기화 주기(
-horizontal-pod-autoscaler-sync-period, 기본 15초)와 스케일 다운 안정화 시간(-horizontal-pod-autoscaler-downscale-stabilization, 기본 5분),--horizontal-pod-autoscaler-initial-readiness-delay변경은 kube-controller-manager level 의 configuration 이므로 고객사 환경에 따라 변경에 제한이 있을 수 있기에, Webhook Server 를 최대한 가볍게 만들어 응답 속도 최적화를 진행하였습니다. (사용자/고객사의 상황에 따라, "Autoscaling이 왜 즉각적으로 진행되지 않나요?", "언제 되나요?", "빨리 trigger 되게 할 수 있나요?" 등의 요청이 들어오면, 해당 값 조정이 필요함을 공유할 수 있습니다.) - Webhook 서버 HA: Webhook 서버에 부하가 몰리는 상황에 대해 유동적으로 대응할 수 있게 배포하였으며, 최소 Replica 수(
minReplicas)와nodeAffinity를 적용하여 단일 실패 지점(SPOF) 상황에 대응할 수 있도록 진행하였습니다.
- Webhook 범위 제한:
- 철저한 테스트: 부하 테스트 도구(
hey)와 리소스 사용량 증가 도구(stress)로 다양한 스케일링 시나리오를 재현하여 쿼터 제한과 파드 수, 리소스 사용량이 예상대로 제어되는지 검증했습니다.
결과 및 효용: 안정적인 Autoscaling과 거버넌스 강화
이렇게 Kubernetes Admission Control 과정에서 Runway 자원 검증 API를 연동함으로써, Autoscaling 상황에서도 자원을 안정적으로 관리할 수 있게 되었습니다. 이는 다음과 같은 실질적인 효용을 제공할 수 있었습니다.
사용자 관점에서 보면, 할당된 자원 한도 내에서 추론 서비스를 운영할 수 있어 비용 예측이 용이해졌습니다. 이로 인해 예기치 않은 비용 발생을 줄일 수 있습니다. 또한, 안정적인 서비스 운영이 가능해졌습니다. 다른 워크스페이스의 과도한 자원 사용으로 인한 서비스 영향, 예를 들어 자원 부족이나 성능 저하를 예방할 수 있게 된 것입니다.
플랫폼 운영자 관점에서는 자원 관리 정책의 통일성이 강화되었습니다. KPA, HPA 등 스케일링 방식에 관계없이 일관된 정책을 적용할 수 있게 되었습니다. 이로 인해 플랫폼 안정성도 향상되었습니다. 특정 서비스가 의도치 않게 자원을 독점하는 상황을 방지함으로써 클러스터 전체의 안정성을 확보할 수 있습니다. 마지막으로 자원 사용량에 대한 효율적인 관리가 가능해져 플랫폼 전체의 자원 소비를 정확하게 제한하고 조절할 수 있게 되었습니다. 사용자는 Autoscale 트리거 시 다음과 같은 notification 을 통해 확인할 수 있습니다.

Runway에서 Autoscale 트리거 시 받는 알림 화면
Autoscaling과 자원 거버넌스의 균형을 찾다
이번 개선 작업은 Dynamic한 Autoscaling의 장점을 유지하면서도, 멀티테넌트 환경에서 필수적인 자원 거버넌스를 확보하는 균형점을 찾는 과정이었습니다.
쿠버네티스의 표준 확장 기능인 Admission Webhook 과 Runway 플랫폼의 정책 관리 기능을 효과적으로 결합하여 해결할 수 있었습니다. 기술 검토 과정에서 다양한 선택지를 검토하고 팀원들과 논의하는 과정을 통해 최종적으로 유지보수 비용은 줄이고 확장성은 높일 수 있는 솔루션을 도입할 수 있었습니다.
기술 검토 과정에서 검토하고 공유했던 여러 기술들은 이후 다른 작업에서 활용되었습니다. Istio Envoy Proxy 사이드카 컨테이너 기반의 EnvoyFilter는 여러 마이크로서비스의 공통된 인증 로직을 서비스 메시 레이어로 분리하는 작업에서 커스텀 스케줄러는 Time Slicing 환경에서 GPU Utilization을 높이는 커스텀 스케줄러를 개발하는 작업에서 각각 활용되었습니다.
마키나락스는 앞으로도 Runway 사용자들이 AI 모델을 더욱 안정적이고 효율적으로 운영할 수 있도록, 클라우드 네이티브 기술의 복잡성을 해결하고 신뢰할 수 있는 MLOps 환경을 제공하기 위해 끊임없이 노력하겠습니다.









