

Running AI in production often raises familiar questions:
"Can I manage user access down to individual menus?”
“Can I deploy LLMs in a close network—without relying on Hugging Face?”
“Can I skip repetitive setup and jump straight into experiments?”
This latest Runway update was designed to answer exactly those questions. In real-world AI operations, success depends on more than just building models. Teams need to manage access, allocate resources efficiently, and run AI securely—even in isolated or air-gapped environments.
Runway is built for these demands—an enterprise-grade platform designed for reliable and scalable AI operations. From training and deployment to resource management, collaboration and security, Runway empowers organizations to move from experimentation to production with confidence.
This release focuses on three powerful new features that offer immediate value to production teams: granular permission management, closed-network LLM serving, and streamlined experiment setup. We’ve also added several practical updates to improve day-to-day operations.
Let’s take a closer look at what’s new in this Runway update—and how it helps teams run AI more efficiently in production.
What’s new in this update
Granular permission management with custom roles
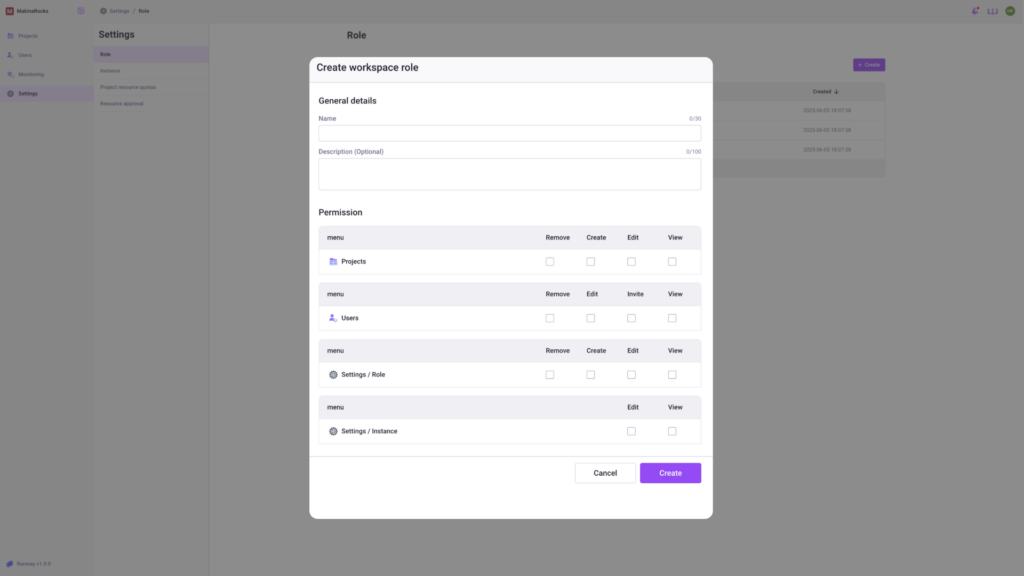 Granular permission management feature
Granular permission management feature
Move beyond rigid, fixed roles. You can now define custom roles and set menu-level access based on your organization’s policies and team structures.
- Create and assign custom roles to users
- Control access at a granular level (project, instance, user settings, etc.)
- Improve security and collaboration by tailoring permissions by team or role
Closed-network LLM serving with internal object storage
Serving LLMs in a closed network
Now you can deploy .safetensors LLMs as inference services directly from internal object storage (e.g., S3, MinIO)—no Hugging Face Hub required. Runway automatically detects essential files like config.json and tokenizer.json for seamless deployment.
- Upload and serve .safetensors models without external dependencies
- Deploy models using internal storage paths (e.g., S3, MinIO) within closed or air-gapped networks
- Get runtime recommendations (e.g., vLLM) for optimized serving
Pre-built experiment environment templates
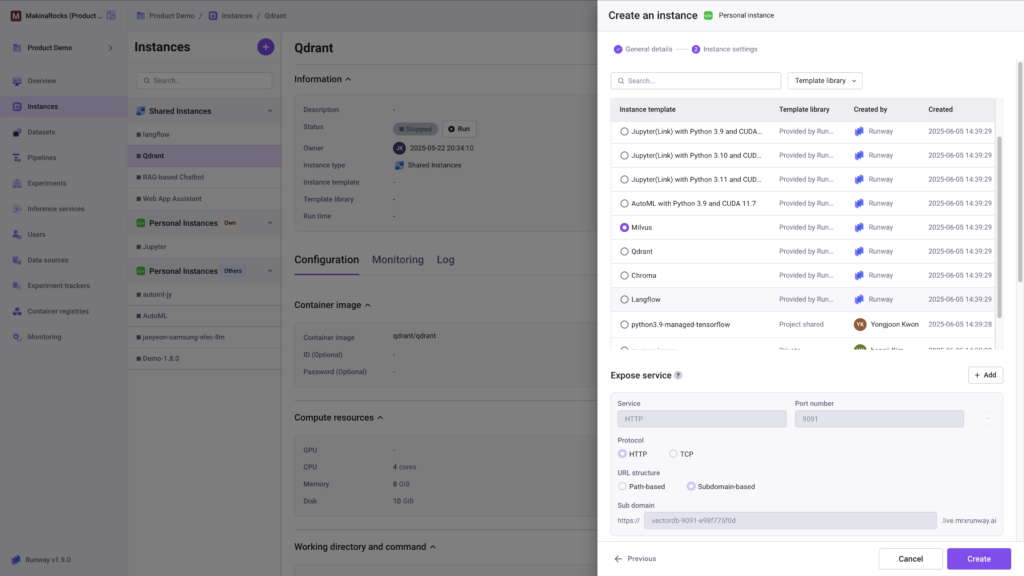 Experiment environment template feature
Experiment environment template feature
Stop setting up environments from scratch. With Runway, you can reuse svaed configurations or instantly launch pre-configured templates that include Langflow, Milvus, Qdrantm Chroma, and more. These templates help teams accelerate development and maintain consistency across experiments, improving both speed and collaboration.
- Built-in templates with popular tools like Langflow
- Save and reuse custom instance environment configurations
- Standardize experiments and share setups across teams
Additional updates
Project approval workflow
- Require admin approval before creating or modifying a project, with full approval history
Project resource quotas
- Set per-project limits for CPU, GPU, memory, and storage resources
Project shared volume settings
- Define and resize shared storage volumes per project—even during runtime
Per-instance resource monitoring
- Monitor real-time CPU, GPU, and memory usage per instance
Resource reclamation
- Admins can manually shut down unused instances to free up compute resources
Try the new features yourself
Want to see how Runway helps streamline AI operations? Request a demo and experience how you can move from experimentation to production—efficiently and reliably.








